
Prometheus是一个开源监控工具,是新一代的云原生监控系统
Prometheus架构
Prometheus的整体架构如下:
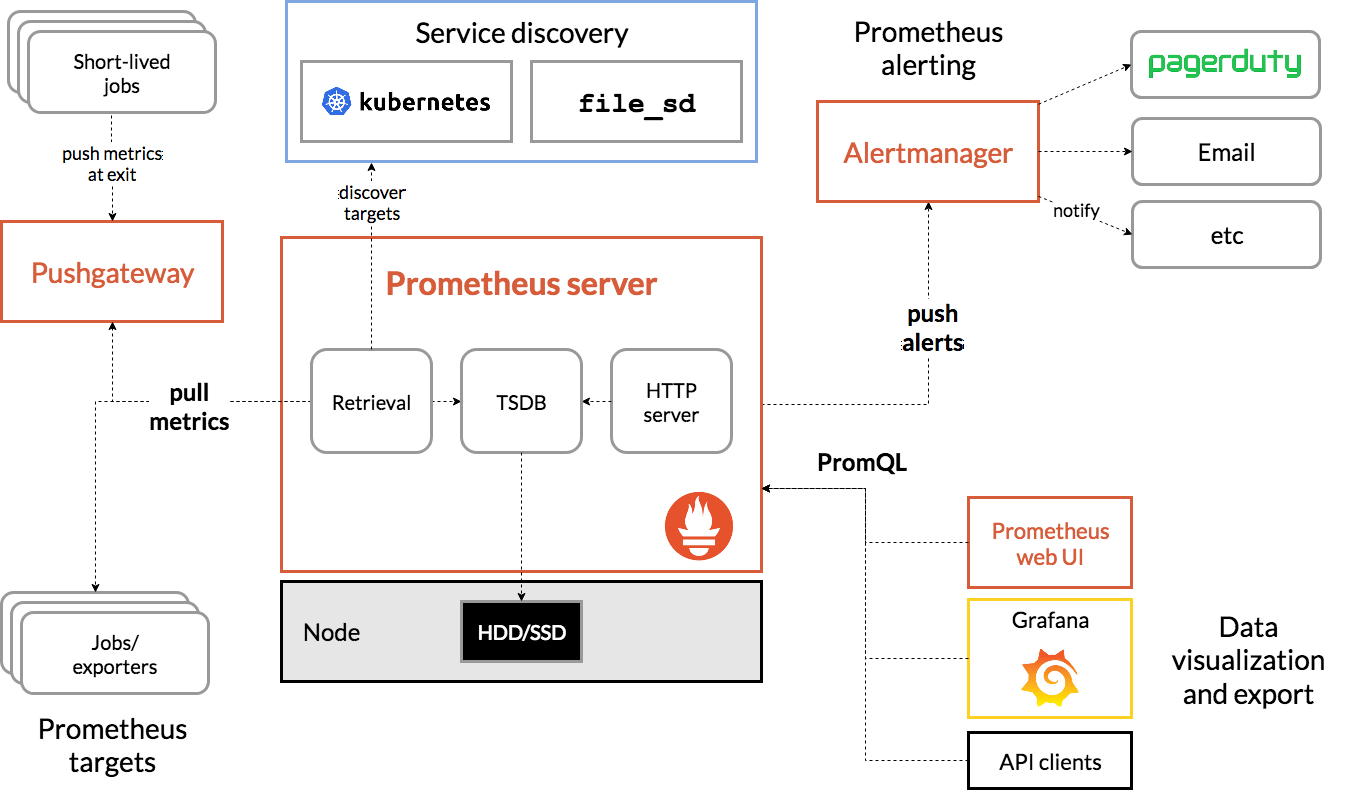
Prometheus Server
Server是Prometheus组件中的核心部分,负责实现对监控数据的获取,存储以及查询。
- 获取数据(Retrival)。Prometheus Server可以通过静态配置管理监控目标,也可以配合使用Service Discovery的方式动态管理监控目标,并从这些监控目标中获取数据。
- 存储数据(Storage)。其次Prometheus Server需要对采集到的监控数据进行存储,Prometheus Server本身就是一个时序数据库,将采集到的监控数据按照时间序列的方式存储在本地磁盘当中。
- 查询数据。最后Prometheus Server对外提供了自定义的PromQL语言,实现对数据的查询以及分析。
Exporters
Exporter将监控数据采集的端点通过HTTP服务的形式暴露给Prometheus Server,Prometheus Server通过访问该Exporter提供的Endpoint端点,即可获取到需要采集的监控数据。
一般来说可以将Exporter分为2类:
- 直接采集:这一类Exporter直接内置了对Prometheus监控的支持,比如cAdvisor,Kubernetes,Etcd,Gokit等,都直接内置了用于向Prometheus暴露监控数据的端点。
- 间接采集:间接采集,原有监控目标并不直接支持Prometheus,因此我们需要通过Prometheus提供的Client Library编写该监控目标的监控采集程序。例如: Mysql Exporter,JMX Exporter,Consul Exporter等。
AlertManager
在Prometheus Server中支持基于PromQL创建告警规则,如果满足PromQL定义的规则,则会产生一条告警,而告警的后续处理流程则由AlertManager进行管理。在AlertManager中我们可以与邮件,Slack等等内置的通知方式进行集成,也可以通过Webhook自定义告警处理方式。AlertManager即Prometheus体系中的告警处理中心。
PushGateway
由于Prometheus数据采集基于Pull模型进行设计,因此在网络环境的配置上必须要让Prometheus Server能够直接与Exporter进行通信。 当这种网络需求无法直接满足时,就可以利用PushGateway来进行中转。可以通过PushGateway将内部网络的监控数据主动Push到Gateway当中。而Prometheus Server则可以采用同样Pull的方式从PushGateway中获取到监控数据。
Service Discovery
在云上所有资源都是弹性的,这些资源可以随着需求规模的变化而变化。例如在AWS的AutoScaling,可以根据用户定义的规则动态地创建或者销毁ECS实例,从而使用户部署在AWS上的应用可以自动的适应访问规模的变化;在Kubernetes中,pod也会随时在创建和被销毁。
这种按需的资源使用方式对于监控系统而言就意味着没有了一个固定的监控目标,所有的监控对象(基础设施、应用、服务)都在动态的变化。对于Prometheus这一类基于Pull模式的监控系统,显然也无法继续使用的static_configs的方式静态的定义监控目标。而对于Prometheus而言其解决方案就是引入一个中间的代理人(服务注册中心),这个代理人掌握着当前所有监控目标的访问信息,Prometheus只需要向这个代理人询问有哪些监控目标控即可, 这种模式被称为服务发现。
Prometheus通过使用平台提供的API就可以找到所有需要监控的云主机。在Kubernetes这类容器管理平台中,Kubernetes掌握并管理着所有的容器以及服务信息,那此时Prometheus只需要与Kubernetes打交道就可以找到所有需要监控的容器以及服务对象。Prometheus还可以直接与一些开源的服务发现工具进行集成,例如在微服务架构的应用程序中,经常会使用到例如Consul这样的服务发现注册软件,Promethues也可以与其集成从而动态的发现需要监控的应用服务实例。
Prometheus部署
服务端部署
1 | # 同步集群时间 |
浏览器访问服务端IP:9090即可查看Prometheus的web页面
客户端部署
Prometheus支持多种客户端,此处以node_exporter为例
部署
1 | # 官网下载软件包 |
浏览器访问客户端IP:9100即可查看客户端的监控信息,默认是9100端口,信息在metrics目录里
服务端获取客户端信息
服务端通过拉取的方式获取客户端的信息,需要修改服务端的配置文件
1 | # 编辑服务端配置文件 |
浏览器访问服务端IP:9090查看Prometheus的web页面,点击Status—>Targets即可看到新加入的客户端信息
配置自动发现
服务端配置文件中,之前的任务都是通过添加静态配置(static_configs)实现的,这样做的缺点是每次添加一个监控项目就得去重启prometheus server,这一点是无法忍受的,因为重启的时候会导致prometheus server在这段时间不可用。所以配置自动发现是必需的。
本次基于文件file_sd实现自动发现,这样做的好处是,在每次添加监控项目时,只需要更改自动发现的配置文件就行了,在文件中添加一个目标主机,无需更改服务端配置文件,也无需重启prometheus server。
file_sd介绍
File Service Discovery (file_sd)是Prometheus中的一种服务发现机制,用于动态地发现和监控目标实例。
File Service Discovery通过读取静态文件(通常是JSON或YAML格式)中定义的目标实例信息来发现服务。这些信息通常包括目标的IP地址、端口以及其他标识信息。当这些信息被添加、更新或移除时,Prometheus会及时地感知到并相应地调整监控目标。
配置
1 | # 编辑服务端配置文件 |
pushgateway部署
通过node-exporter可以收集到各种服务器的相关性指标,但是并没有办法满足我们的定制化需求,比如需要监控某个进程数,某个进程打开的文件数,某个进程消耗的内存等等,这就需要一个定制化的监控项,类似于zabbix的自定义监控项是一个道理。
部署
1 | # 官网下载软件包 |
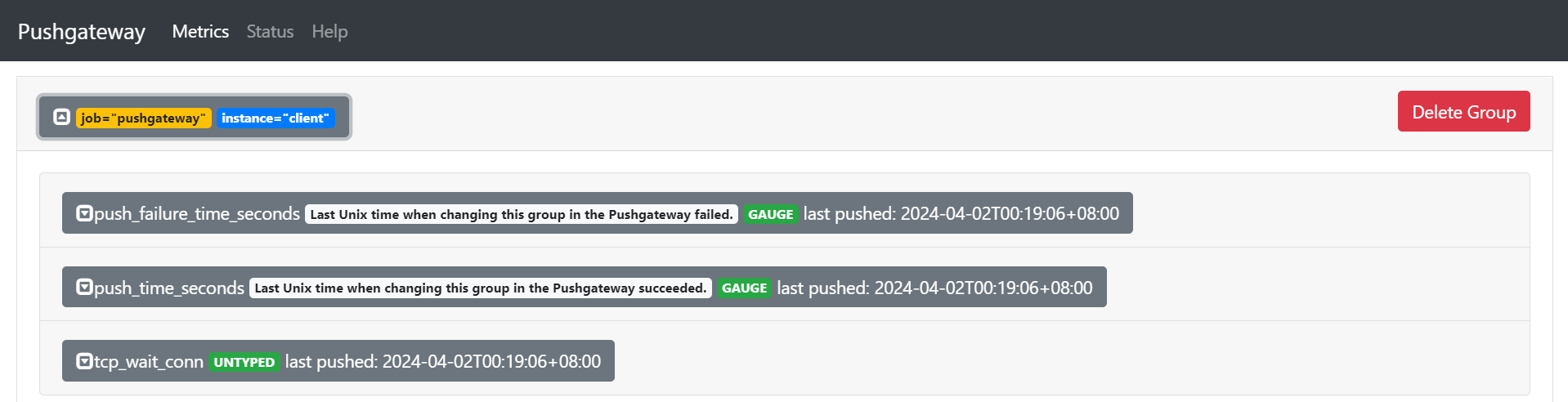
浏览器访问pushgateway服务端IP:9091即可查看客户端的监控信息,默认是9091端口,信息在metrics目录里
自定义监控项
编写脚本发送到pushgateway
1 | # 编写脚本,添加以下内容,脚本的作用是将`metrics_name metrics_value`以二进制的形式发送到pushgateway服务端 |
浏览器访问pushgateway服务端IP:9091即可查看客户端新推送的监控信息
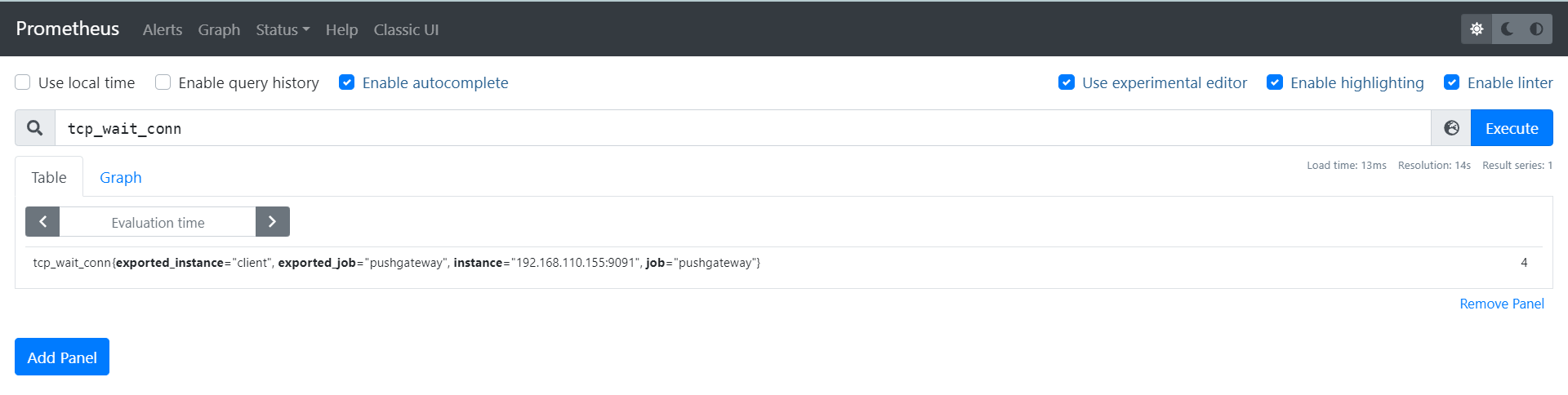
在Promtheus服务端web页面,搜索metrics名称tcp_wait_conn也能看到监控项的数据
定时推送
1 | # 编写定时任务,每10s推送一次 |
alertmanager部署
Alertmanager是Prometheus体系中告警的统一处理中心。
在Prometheus Server中可以基于PromQL表达式定义告警触发条件(告警规则),Prometheus后端对这些触发规则进行周期性计算,当满足触发条件后则会触发告警通知。默认情况下,用户可以通过Prometheus的Web界面查看这些告警规则以及告警的触发状态。
当Promthues与Alertmanager关联之后,可以将告警发送到Alertmanager中并通过Alertmanager可以对这些告警进行进一步的处理。Alertmanager提供了多种内置第三方告警通知方式,同时还提供了对Webhook通知的支持,通过Webhook用户可以完成对告警更多个性化的扩展。
部署
1 | # 官网下载软件包 |
浏览器访问alertmanager服务端IP:9093即可查看告警端的信息,默认是9093端口
服务端配置
1 | # 更改prometheus配置文件 |
告警规则文件
1 | vim alert_rules.yml # 此文件在服务端的配置文件中有定义位置 |
此时如果pushgateway停止运行,评估10s后会发送邮件告警,pushgateway恢复运行后,会自动发送恢复邮件。