Kubernetes简称k8s,是用于管理容器化应用程序集群的工具,是一个容器编排工具。
说起容器编排,像Docker的Compose或者是Docker-Swarm都提供了简单的容器编排的能力,它们的通病就是过于以Docker核心,提供的能力也过于简单比如定义谁先启动谁后启动,无法满足比较复杂的场景。而K8S的容器编排设计是站在更高的维度,可以协调地将许多微服务组合在一起构成了应用程序,并且自动且持续地监视集群并对其组成进行调整。
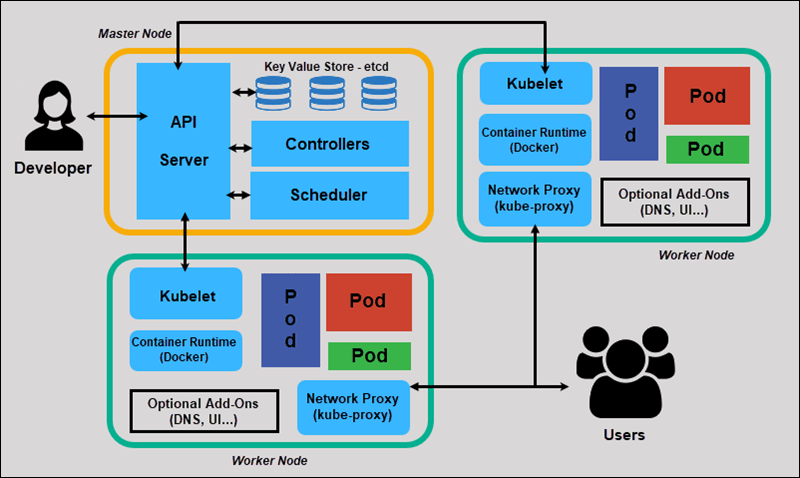
K8s架构 很重要的架构图
Master Node是主节点,它负责管理Worker Node(工作节点)。Master Node 通过API Server从CLI(命令行界面)或UI(用户界面)接收命令输入。在生产中通常会有多个Master Node以实现K8s系统服务高可用。
其实K8s官方并没有Master Node这一说,只是大多数安装工具(kubeadm)或者脚本为了架构更明了会把所有组件安装到一台机器上即Master机器,并且不会在此机器上运行用户容器。 这不是强制性的,所以也可以对这些控制组件实行分布式部署,不过这样的话高可用会是一个不小的挑战。
Master Node 在Master Node上通常包括 API Server、etcd 存储、Controller-manager、Scheduler、cloud-controller-manager(云控制中心,可选,用于云产品)和用于 K8s 服务的 DNS 服务器(插件)。
API Server
API Server是用户唯一可以直接进行交互的K8s组件,它为K8s集群资源操作提供唯一入口,并提供认证、授权、访问控制、API 注册和发现机制。
ControllerManager
ControllerManager是控制器,它可以实时监控集群中如Service等各种资源的状态变化,不断尝试将它们维持在一个期望的状态。
k8s在后台运行许多不同的控制器进程,包括:
节点控制器(Node Controller): 负责在节点出现故障时进行通知和响应
任务控制器(Job controller): 监测代表一次性任务的 Job 对象,然后创建 Pods 来运行这些任务直至完成
端点控制器(Endpoints Controller): 填充端点(Endpoints)对象(即加入 Service 与 Pod)
服务帐户和令牌控制器(Service Account & Token Controllers): 为新的命名空间创建默认帐户和 API 访问令牌
从逻辑上讲,每个控制器都是一个单独的进程, 但是为了降低复杂性,它们都被编译到同一个可执行文件,并在一个进程中运行。
cloud-controller-manager
cloud-controller-manager是云控制器,是可选的组件,它可以将集群连接到云提供商的 API 之上,大多数非混合的云环境是用不到这个组件的。它与ControllerManager类似,将若干逻辑上独立的控制回路组合到同一个可执行文件中,以同一进程的方式运行。
kube-scheduler
kube-scheduler是调度器, 负责监视新创建、未指定运行Node的 Pods,决策出一个让pod运行的节点。
例如,如果应用程序需要 1GB 内存和 2 个 CPU 内核,那么该应用程序的 pod 将被安排在至少具有这些资源的节点上。每次需要调度 pod 时,调度程序都会运行。调度程序必须知道可用的总资源以及分配给每个节点上现有工作负载的资源。
调度决策考虑的因素包括单个 Pod 和 Pod 集合的资源需求、硬件/软件/策略约束、亲和性和反亲和性规范、数据位置、工作负载间的干扰和最后时限。
etcd
etcd 是兼具一致性和高可用性的键值数据库,可以作为保存 K8s 所有集群数据的后台数据库。 在生产级k8s中的etcd通常会以集群的方式存在,安全原因,它只能从 API 服务器访问。
Worker Node 和MasterNode类似,WorkerNode本质也并不是一个独立的应用程序,它包含 Kubelet 、kube-porxy 以及服务于pod的容器运行时(runtime)。当然也会有外部storage与registry用于为容器提供存储与镜像仓库服务。
kubelet
kubelet是集群中每个Worker Node上都运行的代理。它监视从API Server发送来的任务,执行任务并报告给主节点。它还会监视Pod,确保 pod 及容器健康并以所需状态运行。该组件还向 API Server 报告运行它的主机的健康状况。
kubelet 不会管理不是由 K8s 创建的容器。
kube-proxy
kube-proxy是集群中每个Worker Node上都运行的网络代理。它用于处理单个主机子网划分并向外部公开服务。
kube-proxy 维护节点上的网络规则。这些网络规则允许从集群内部或外部的网络会话与 Pod 进行网络通信。
容器运行时(Container Runtime)
容器运行时负责创建容器运行环境。
Kubernetes 支持多个容器运行时: Docker(即将被废弃)、containerd、CRI-O以及任何实现 Kubernetes CRI (容器运行环境接口) 的runtime。
K8s基本工作流程
kubectl 客户端首先将CLI命令转化为RESTful的API调用,然后发送到kube-apiserver。
kube-apiserver 在验证这些 API 调用后,将任务元信息并存储到etcd,接着调用 kube-scheduler 开始决策一个用于作业的Node节点。
一旦 kube-scheduler 返回一个适合调度的目标节点后,kube-apiserver 就把任务的节点信息存入etcd,并创建任务。
此时目标节点中的 kubelet正监听apiserver,当监听到有新任务需要调度到本节点后,kubelet通过本地runtime创建任务容器,执行作业。
接着kubelet将任务状态等信息返回给apiserver存储到etcd。
这样我们的任务已经在运行了,此时control-manager发挥作用保证任务一直是我们期望的状态
K8s部署 Master部署
etcd部署
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 [root@master ~]$ yum install etcd -y [root@master ~]$ rpm -ql etcd /etc/etcd /etc/etcd/etcd.conf /usr/bin/etcd /usr/bin/etcdctl /usr/lib/systemd/system/etcd.service [root@master etcd]$ vim etcd.conf ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379" [root@master ~]$ systemctl enable etcd [root@master ~]$ systemctl start etcd
1 2 3 4 5 6 7 8 9 10 11 12 13 14 etcdctl --help backup 备份一个etcd数据库 cluster-health 检查数据库的健康状况 mk 创建一个新的键值对:etcdctl mk <key> <value> mkdir 创建一个新的目录:etcdctl mkdir <key> rm 移除一个键值对或目录: etcdctl rm <key> rmdir 移除一个空目录或者键值对:etcdctl rmdir <key> get 根据键名检索键值:etcdctl get <key> ls 检索目录 set 给键名设置一个键值:etcdctl set <key> <value> update 更新一个已存在的键名的键值:etcdctl update <key> <value>
master部署
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 [root@master kubernetes]$ yum install -y kubernetes-master [root@master kubernetes]$ rpm -ql kubernetes-master /etc/kubernetes /etc/kubernetes/apiserver /etc/kubernetes/config /etc/kubernetes/controller-manager /etc/kubernetes/scheduler /run/kubernetes /usr/bin/hyperkube /usr/bin/kube-apiserver /usr/bin/kube-controller-manager /usr/bin/kube-scheduler /usr/lib/systemd/system/kube-apiserver.service /usr/lib/systemd/system/kube-controller-manager.service /usr/lib/systemd/system/kube-scheduler.service /usr/lib/tmpfiles.d/kubernetes.conf [root@master kubernetes]$ vim apiserver KUBE_API_ADDRESS="--insecure-bind-address=0.0.0.0" KUBE_ETCD_SERVERS="--etcd-servers=http://127.0.0.1:2379" KUBE_SERVICE_ADDRESSES="--service-cluster-ip-range=10.254.0.0/16" [root@master kubernetes]$ vim config KUBE_LOGTOSTDERR="--logtostderr=true" KUBE_LOG_LEVEL="--v=0" KUBE_ALLOW_PRIV="--allow-privileged=false" KUBE_MASTER="--master=http://127.0.0.1:8080" [root@master kubernetes]$ systemctl enable kube-apiserver kube-controller-manager kube-scheduler [root@master kubernetes]$ systemctl start kube-apiserver kube-controller-manager kube-scheduler [root@master kubernetes]$ kubectl get cs NAME STATUS MESSAGE ERROR etcd-0 Healthy {"health" :"true" } scheduler Healthy ok controller-manager Healthy ok
Node部署 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 [root@node1 ~]$ yum install kubernetes-node -y [root@node1 ~]$ rpm -ql kubernetes-node /etc/kubernetes /etc/kubernetes/config /etc/kubernetes/kubelet /etc/kubernetes/proxy /etc/systemd/system.conf.d/kubernetes-accounting.conf /run/kubernetes /usr/bin/hyperkube /usr/bin/kube-proxy /usr/bin/kubelet /usr/lib/systemd/system/kube-proxy.service /usr/lib/systemd/system/kubelet.service /usr/lib/tmpfiles.d/kubernetes.conf [root@node1 kubernetes]$ vim config KUBE_MASTER="--master=http://192.168.110.160:8080" [root@node1 kubernetes]$ vim kubelet KUBELET_ADDRESS="--address=127.0.0.1" KUBELET_HOSTNAME="--hostname-override=192.168.110.161" KUBELET_API_SERVER="--api-servers=http://192.168.110.160:8080" KUBELET_POD_INFRA_CONTAINER="--pod-infra-container-image=registry.access.redhat.com/rhel7/pod-infrastructure:latest" [root@node1 kubernetes]$ systemctl enable kubelet kube-proxy [root@node1 kubernetes]$ systemctl start kubelet kube-proxy [root@master kubernetes]$ kubectl get node NAME STATUS AGE 192.168.110.161 Ready 14m 192.168.110.162 Ready 2m 192.168.110.163 Ready 1m 192.168.110.164 Ready 49s
补充:上面说到kubelet可以监控容器的健康状态,这是因为kubelet中内置了cadvisor,浏览器访问http://node节点IP:4194可以查看
网络插件部署 网络插件使用的是flannel,所有节点都需要安装并启动
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 [root@node1 kubernetes]$ yum install -y flannel [root@node1 kubernetes]$ rpm -ql flannel /etc/sysconfig/flanneld /run/flannel /usr/bin/flanneld /usr/bin/flanneld-start /usr/lib/systemd/system/docker.service.d/flannel.conf /usr/lib/systemd/system/flanneld.service /usr/lib/tmpfiles.d/flannel.conf [root@node1 sysconfig]$ vim flanneld FLANNEL_ETCD_ENDPOINTS="http://192.168.110.160:2379" FLANNEL_ETCD_PREFIX="/atomic.io/network" etcdctl mk /atomic.io/network/config '{"Network":"172.18.0.0/16","Backend":{"Type":"vxlan"}}' [root@master etcd]$ systemctl enable flanneld.service [root@master etcd]$ systemctl start flanneld.service
注意:部署网络插件之后,在不同节点运行容器可能无法互相ping通,这可能是因为默认的转发策略是DROP,需要修改为ACCEPT,解决方法:
1 2 3 4 5 6 7 8 9 iptables -P FORWARD ACCEPT iptables-save > /etc/sysconfig/iptables vim /usr/lib/systemd/system/docker.service ExecStartPost=/usr/sbin/iptables -P FORWARD ACCEPT systemctl daemon-reload && systemctl restart docker