
ReplicationController资源
Replicationcontroller是k8s的一种副本控制器,简称rc,它有一个单独的模板文件,通过标签选择器来关联pod,可以保证指定数量的pod始终存活。
ReplicationController是k8s早期版本的控制器(比如K8S 1.7),现在K8S都更新到K8S 1.22版本了,因此这种控制器早已被废弃,仅作了解。
rc相关命令
创建rc
1 | kubectl create -f rc模板文件 # 创建rc资源 |
修改rc
1 | kubectl edit -f rc模板文件 # 通过文件名编辑rc资源 |
删除rc
1 | kubectl delete rc rc名称 |
查看rc
1 | kubectl get rc |
创建rc流程
跟创建pod的流程类似,通过rc模板来创建,此处仅给出一个简单的rc模板
1 | apiVersion: v1 |
创建了一个rc资源之后,rc资源会根据模板文件中的配置拉起5个容器,通过kubectl get all查看所有资源
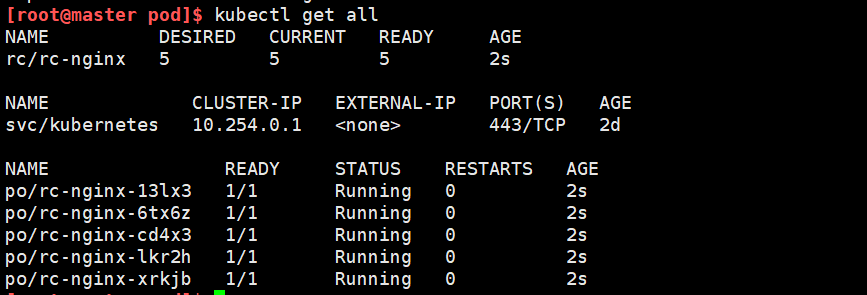
此时删除任意数量的pod,rc资源都会立刻再拉起5个pod资源。删除掉rc资源,pod会被删除。
rc滚动升级
在k8s中可以实现pod的滚动升级,可以使用此条命令
1 | kubectl rolling-update 旧的控制器名称 --image=新的容器镜像 |
在上面的例子中,使用rc资源中的pod进行滚动升级,将nginx版本升级到1.16,大致的流程是先建立一个新版本的pod,然后删除一个旧版本的pod,直到新版本的pod达到期望的数量。下面是两种方式的详细解释:
基于定义文件
对pod进行升级,依赖rc中的标签选择器,旧的rc资源和新的rc资源,标签中的key必须是相同的,但是value必须至少有一个不同,这样才能区分不同的rc资源。
1 | # 查看新的rc资源的定义文件 |
基于镜像
1 | # 只需要指定镜像即可 |
这种方式不需要编写新的rc文件,只需要指定镜像即可。至于它是如何区分新旧两种rc资源的,在滚动更新的过程中可以看出:
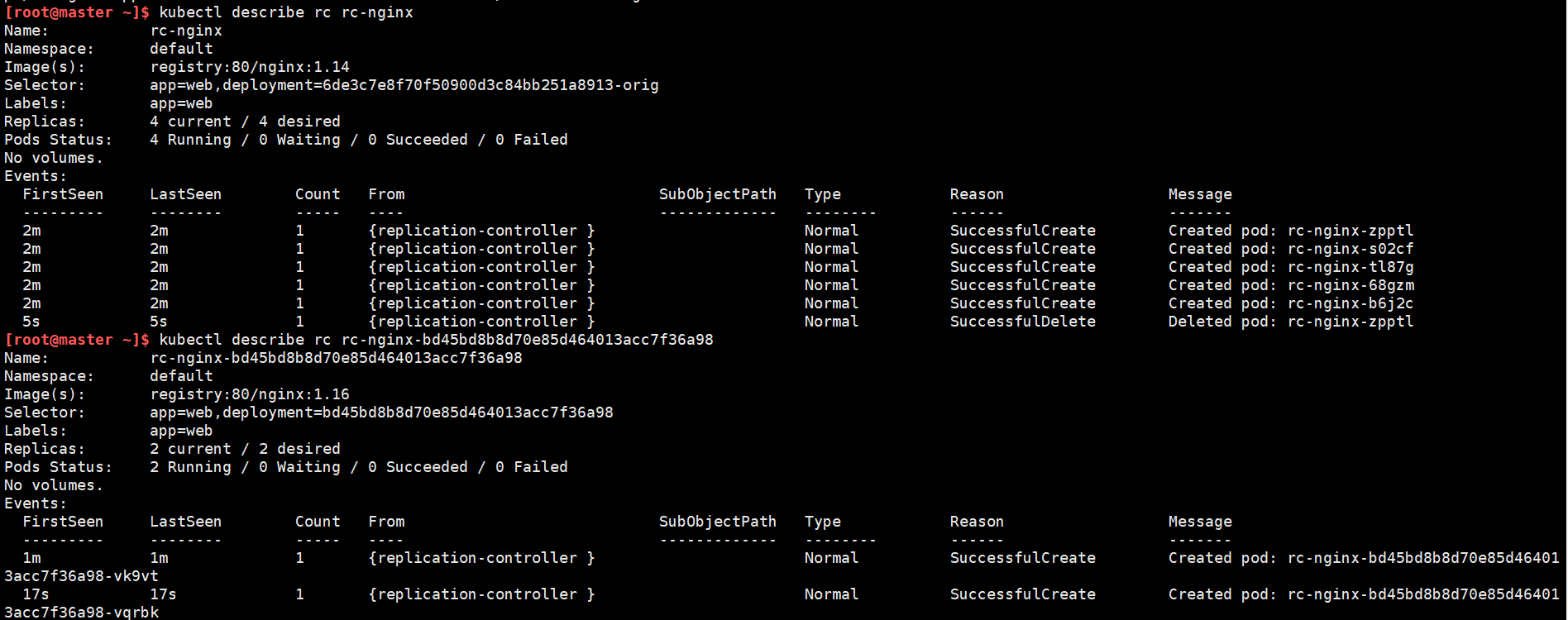
它自动创建了一个rc资源,资源名是在旧rc资源名上增加了一串序列号,同时给新旧两种资源的标签选择器都自动增加了一个deployment的key,并且分别赋了不同的value,它们创建的pod也自动增加了这样的一个标签,以此来实现区分。

Service资源
svc介绍
rc资源只能实现副本数量的控制,仅仅有rc资源是远远达不到管理集群的要求的,还需要Service资源(简称svc)的介入。

Service资源可以为一组Pod提供对外提供统一访问入口和负载均衡的能力,Service通过标签关联一组Pod,当有客户端访问工作节点的Service时,它会根据相应的负载均衡策略找到后端的Pod以提供服务。
Service使用iptable或者ipvs为一组Pod提供负载均衡能力,在早期版本中,默认使用的是iptables规则,优点是灵活且功能强大,缺点是需要从上至下遍历匹配和更新规则,因此在集群规模过大时,每次都需要遍历大量的规则,导致性能降低。k8s的1.8+版本中推荐使用lvs规则,它工作在内核态,有更好的性能,并且调度算法丰富:”rr”,”wrr”,”lc”,”wlc”,”ip hash”等;
svc相关命令不再赘述
创建svc流程
svc也是根据标签选择器来关联一组pod的,创建方式与创建pod类似,此处仅给出svc模板文件
1 | apiVersion: v1 |
在上面的情况中,使用的是svc的NodePort类型,这种类型适用于对K8S集群外部暴露应用,svc会在每个Node上启用一个端口来暴露服务,此处是30000端口,在集群外部访问http://任意Node节点IP:30000,会先访问到svc资源,它有一个VIP,相当于访问了VIP的8888端口,然后根据负载均衡策略,将请求分配到某个节点的80端口。
在实际情况中,对外暴露所有Node的IP是不合适的,需要在Node集群前加一个公网负载均衡器为项目提供统一访问入口,可以使用主流开源的负载均衡器Nginx、Lvs等,也可以使用公有云类似SLB的解决方案。
1 | # 基于命令行的方式创建svc用于暴露一些端口或资源 |
Replicaset资源
ReplicaSet是kubernetes中的另一种副本控制器,简称rs,是k8s较新的版本中使用的控制器,主要作用跟rc相似,保证一定数量的Pod能够在集群中正常运行。
ReplicaSet也是通过标签选择器来关联pod的,下面给出一个Replicaset定义文件(仅作了解)
1 | apiVersion: apps/v1 |
官方推荐不要直接使用ReplicaSet,而是用Deployments取而代之,Deployments是比ReplicaSet更高级的概念,它会管理ReplicaSet并提供很多其它有用的特性,最重要的是Deployments支持声明式更新,声明式更新的好处是不会丢失历史变更。所以Deployment控制器不直接管理Pod对象,而是由 Deployment 管理ReplicaSet,再由ReplicaSet负责管理Pod对象。
声明式定义:指直接修改资源清单yaml文件,然后通过kubectl apply -f 资源定义文件,就可以更改资源
Deployment资源
无论是rc还是rs,它们的作用只是确保指定数量的 Pod 始终在运行,缺乏更高级的功能,如滚动更新、版本回滚等,并且ReplicationController 使用基本的标签选择器来匹配 Pod,并不支持高级选择器,使得它在某些部署场景下显得不够灵活。此时需要引入Deployment资源(简称deploy)。
Deployment控制器会创建一个新的ReplicaSet控制器,通过ReplicaSet创建pod,删除Deployment控制器,也会删除Deployment控制器下对应的ReplicaSet控制器和pod资源
相关命令不再赘述,下面给出一个简单的Deployment模板文件,与rc的模板文件很相似
1 | apiVersion: extensions/v1beta1 # 注意观察这个API的版本编号,在后期的版本中其是有变化的! |
使用kubectl apply -f deploy文件创建一个deploy资源之后,查看:
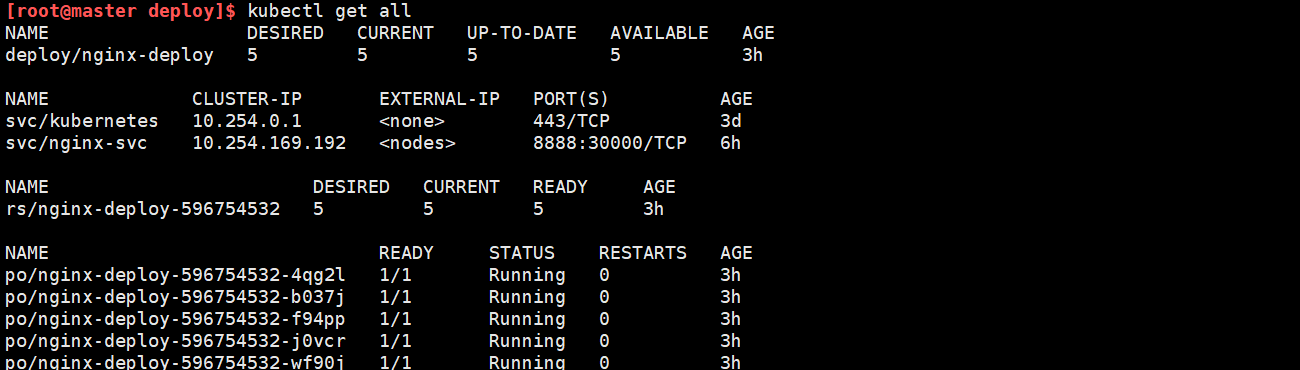
另一种方式,通过命令行快速创建一个deployment资源
1 | kubectl run NAME --image=image [--env="key=value"] [--port=port] [--replicas=replicas] [--dry-run=bool] |
pod扩缩容
因为Deployment资源支持声明式更新,所以直接修改资源定义文件并应用就可以实现资源更新
1 | # 方式1 |
弹性伸缩
K8S把弹性伸缩分为两类:垂直伸缩(VPA)和水平伸缩(HPA),在pod的维度上,垂直伸缩是指自动调整应用的资源分配(增大/减少pod的cpu、内存占用等),水平伸缩是指自动调整Pod的副本集数量,目前比较成熟的是水平伸缩(HPA)。
HPA是使用巡检(Control Loop)的机制来采集Pod资源使用情况的,默认采集间隔为15s,通过CPU的使用率作为监控指标,当Pod的平均CPU使用率达到预设的值,就会触发扩缩容机制,命令如下:
1 | kubectl autoscale (-f FILENAME | TYPE NAME | TYPE/NAME) [--min=MINPODS] --max=MAXPODS [--cpu-percent=CPU] [flags] |
滚动升级
与扩缩容的方式类似
1 | # 方式1 |
自定义滚动更新策略
滚动更新的策略主要是两个参数:maxSurge和maxUnavailable
1 | maxSurge: 2 # 和期望的副本数相比,超过期望副本数最大值),这个值调的越大,副本更新速度越快。 |
回滚
每次deploy资源的变更都会留有变更记录,支持回滚到历史版本
1 | [root@master deploy]$ kubectl rollout history deployment deploy资源名 # 此处的资源名是nginx-delpoy |