
:star:容器架构
OCI
OCI全称为Open Container Initiative,开放容器倡议
其目的主要是为了制定容器技术的通用技术标准,主要包含两种标准:
容器运行时标准 (runtime spec)
容器镜像标准(image spec)
docker分层架构
Docker最初是一个单体系统,本身提供了尽可能完善的功能。OCI标准出现之后,为了实现解耦,Docker1.11版之后由单体分为了5大组成部分
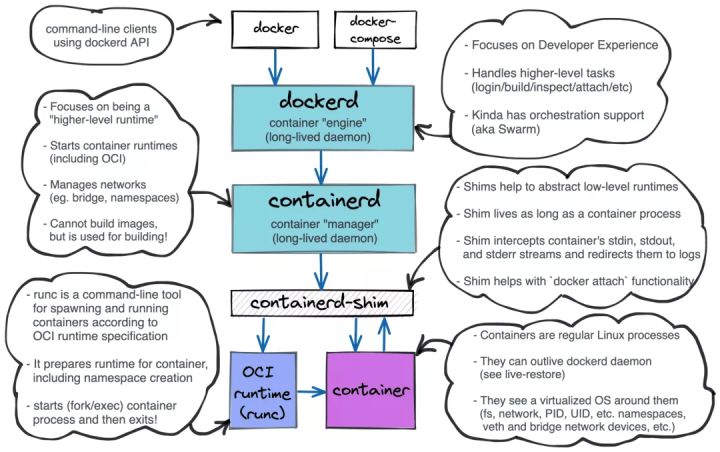
- docker-client:客户端命令
- docker daemon:docker守护进程,主要提供客户端命令接口,比如登陆镜像仓库,镜像构建、存储卷管理、日志操作等。
- containerd:独立负责容器运行时的生命周期(如创建、启动、停止、暂停、信号处理、删除)。
- containerd-shim:每创建一个容器,containerd服务都会创建一个containerd-shim进程,然后该进程调用runc来具体创建容器。
- runc:早期由Docker拿出来捐赠给了OCI来作为容器运行时的标准。使用runc创造出来的就是一个符合oci规范的标准容器。
它们的层级关系如下:
1 | dockerd |
runtime
runtime翻译为容器运行时,指的就是用来管理镜像或者容器的服务端软件。
runtime分为两大类
high-level runtime
比如docker、containerd、podman等,支持更多高级功能(如镜像管理和gRPC / Web API),对于高级别运行时来说,他们是通过调用低级别运行时来管理容器(可以简单的理解为高级别是在低级别基础上的上层封装),一般可以是runc作为低级别运行时。
low-level runtime:
比如lxc、runc、gvisor、kata等,只涉及到容器运行的一些基础细节,比如namespace创建、cgroup设置。
:star:namespace
基本概念
linux在2.4.19内核中开始引入名称空间(namespace),是内核中强大的特性,可以使每个进程看起来都拥有自己的隔离的全局系统资源,即每个进程都有自己的命名空间,每个进程中运行的应用程序都像是运行在一个独立的系统中一样。
区别与k8s中的命名空间,容器中命名空间的目的,是保证容器之间的运行环境(使用时资源)互相隔离,彼此互不影响
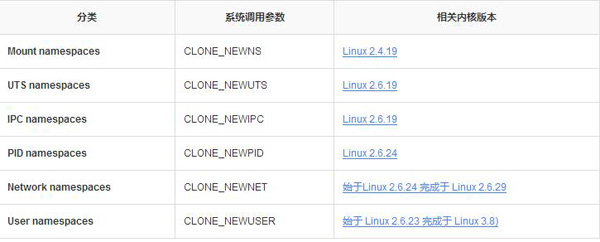
namespace主要隔离了6钟关键资源:
pid
保证不同名称空间里拥有自己完全独立的一套pid号。在不同的名称空间里,即便pid号一样,也不会冲突
uts
主机名与网络信息服务
ipc
ipc的全称是进程间通信,是unix/linux下进程直接通信的一种方式
mount
容器内挂载点与系统分离开
network
用于隔离网络资源(IP地址,网卡、路由),一个名称空间里可以有独立的网卡,监听的端口不会与其他名称空间冲突
user
用户的id、组id不与其他名称空间冲突
通过系统调用创建一个进程
在Linux系统中,创建一个进程是通过clone()系统调用,下面的例子是以容器的方式,创建一个子进程
用C语言编写一个文件clone.c
1 |
|
编译并运行clone.c
1 | # 编译 |
上面的例子仅仅是通过系统调用创建了一个进程,并没有涉及命名空间的隔离,事实上在创建容器进程的时候,还会传入下面的系统调用参数来实现名称空间隔离。
网上一直有一种说法,认为容器本质上是一个进程,其实这个说法并不准确。
创建一个容器,本质上只是创建了一个命名空间,这个命名空间里面可以有不只一个进程,这些进程是通过clone()系统调用创建的,并且通过其他的系统调用使进程的其他资源都加入到了这个命名空间,实现资源隔离,并通过cgroup技术实现资源限制,与其他命名空间的进程互不影响。
所以容器本质上是 命名空间+cgroup 的概念,不能单纯理解为一个进程。
详细的例子参考:深入分析Linux名称空间
:star:UnionFS
基本概念
操作系统镜像
操作系统镜像的本质就是一个iso格式的压缩包,操作系统镜像里面存放了该系统所有的内容,具体来说分为两大部分
一个典型的 Linux 文件系统由 bootfs 和 rootfs 两部分组成
bootfs(boot file system)
主要包含 bootloader 和 kernel,bootloader 主要用于引导加载 kernel,当 kernel 被加载到内存中后 bootfs 会被 umount 掉,从而释放内存,同样的内核版本不同Linux发行版,其bootfs都是一致的。
rootfs (root file system)
包含典型 Linux 系统中的/dev,/proc,/bin,/etc 等标准目录和文件。Linux系统在启动时,rootfs首先会被挂载为只读模式,然后在启动完成后被修改为读写模式,随后它们就可以被修改了。不同的 linux 发行版(如 ubuntu 和 CentOS ) 在 rootfs 这一层会有所区别,体现发行版本的差异性。
容器镜像
容器本质是没有内核的,它只有rootfs,至于下层的bootfs内核部分是共享自物理机的,容器镜像其实就是把rootfs打包到一起(镜像的本质就是一种压缩包),这个rootfs系统里包含了各种依赖文件,以及应用程序文件。
如果想在宿主机上启动容器,让它们拥有操作系统,首先要做的就是把容器的镜像下载到宿主机,然后把容器的镜像文件关联给容器。这种关联的方式一定不能是把镜像文件解压到每一个容器的命名空间内,虽然这样也能实现,但是如果使用同一镜像启动多个容器的时候,会造成极大的存储空间浪费。
所以对于容器来说,具体做法是把镜像里的rootfs目录都mount挂载到容器名称空间内。因为namespace中隔离的诸多资源中就包括mount挂载,如此,哪怕是同一个镜像,mount到了不同的容器或者说名称空间里,肯定是与其他容器/名称空间隔离的。
联合文件系统
为了不影响镜像的一致性,镜像目录是以只读的方式挂载到容器内的,那么容器内也需要增删改查操作,这是通过联合文件系统UnionFS来实现的。
容器内的rootfs根文件系统类型,并不是大在普通linux节点上看到的Ext4或者XFS之类的常见文件系统,而是Overlay,Overlay是一种联合文件系统UnionFS,联合文件系统顾名思义,可以把文件系统上多个目录(分支)内容联合挂载到同一个目录下,使用者也就是容器看起来认为是一个目录,而实际上在物理机里是由多个目录构成的。
OverlayFS使用两个目录,把一个目录置放于另一个之上,并且对外提供单个统一的视角。这两个目录通常被称作层,这个分层的技术被称作union mount。术语上,下层的目录叫做lowerdir,上层的叫做upperdir。对外展示的统一视图称作merged
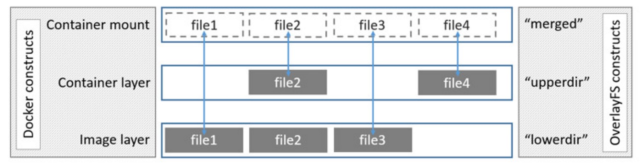
lowerdir就是镜像层,是只读的。
upperdir是容器层,修改相关的内容都在这里存放。
merged是容器映射层,我们在容器里看到的就是这一层,所以该层也可以称之为展现层。
容器挂载分析
OverlayFS 的一个 mount 命令牵涉到四类目录,分别是 lower,upper, merged 和 work
1 | # 查看一个容器中的挂载情况 |
LowerDir
这层里的文件是不会被修改的(只读),在这个例子里我们只有一个 lower/ 目录,不过 OverlayFS 是支持多个 lowerdir 的。
UpperDir
在 OverlayFS 中,如果有文件的创建,修改,删除操作,那么都会在这一层反映出来,它是可读写的。
MergedDir
它是挂载点(mount point)目录,也是用户看到的目录, 用户的实际文件操作在这里进行。
WorkDir
这个目录只是一个存放临时文件的目录, OverlayFS 中如果有文件修改,就会在中间过程中临时存放文件到这里。
补充:
LowerDir可能只由一个目录组成,也可能由很多目录组成,一些从官网拿到的镜像,可能里面只包含一个目录,我们用该镜像启动一个容器,那lowerdir里只包含一个目录。然后我们对该容器进行一系列增删改操作,丢记录到了upperdir里,如果此时镜像销毁,那么uppdir里的内容就丢失,我们可以用docker commit把一个正在运行的容器导出为里一个新镜像,这样upperdir里的内容就保存下来,新镜像里的LowerDir有两个目录,一个是原始镜像的目录,一个是导出upperdir里的东西。
详细分析参考:容器的镜像与UnionFS
:star:cgroup
基本概念
cgroup是一种用来限制容器对宿主机资源使用量的一种机制。
使用cgroup来限制容器对宿主机资源的使用上限,避免单个容器无限占用宿主机资源而影响到其他容器,从而保证了宿主机上容器运行的稳定性。
cpu cgroup
基本概念
使用top命令可以查看操作系统中的cpu状态信息:
1 | us:用户态进程占用cpu时间的百分比,不包括低优先级进程的用户态时间(nice值1-19) |
在Linux系统中,关于cpu的使用情况有两个参考指标:
cpu使用率
某个用户进程对cpu的利用率 = 用户进程占用的cpu时间(包括用户态us+内核态sy) / cpu经历的这段总时间, 利用率为100%代表使用1颗cpu,如果宿主机只有4颗cpu,那么某个进程对cpu的利用率最多400%。top命令上方可以显示所有进程总的cpu使用率,这个使用率是不会超过100%的。
load average
load average是指在某段时间内平均活跃的进程数 / cpu个数,它与cpu使用率不同的是,它统计的进程包括计算任务和io任务,即系统处于可运行状态以及不可中断状态的平均进程数(D状态)。
有些时候会遇到容器里的应用运行速度非常慢,但是所有容器进程、以及宿主机的cpu使用率都很低,内存也很充足的情况。这时候需要查看查看宿主机的load average,如果这个数值很高,说明系统中存在大量的不可中断状态的进程,大多是在等待IO,拖慢了系统运行速度。
cpu cgroup的使用
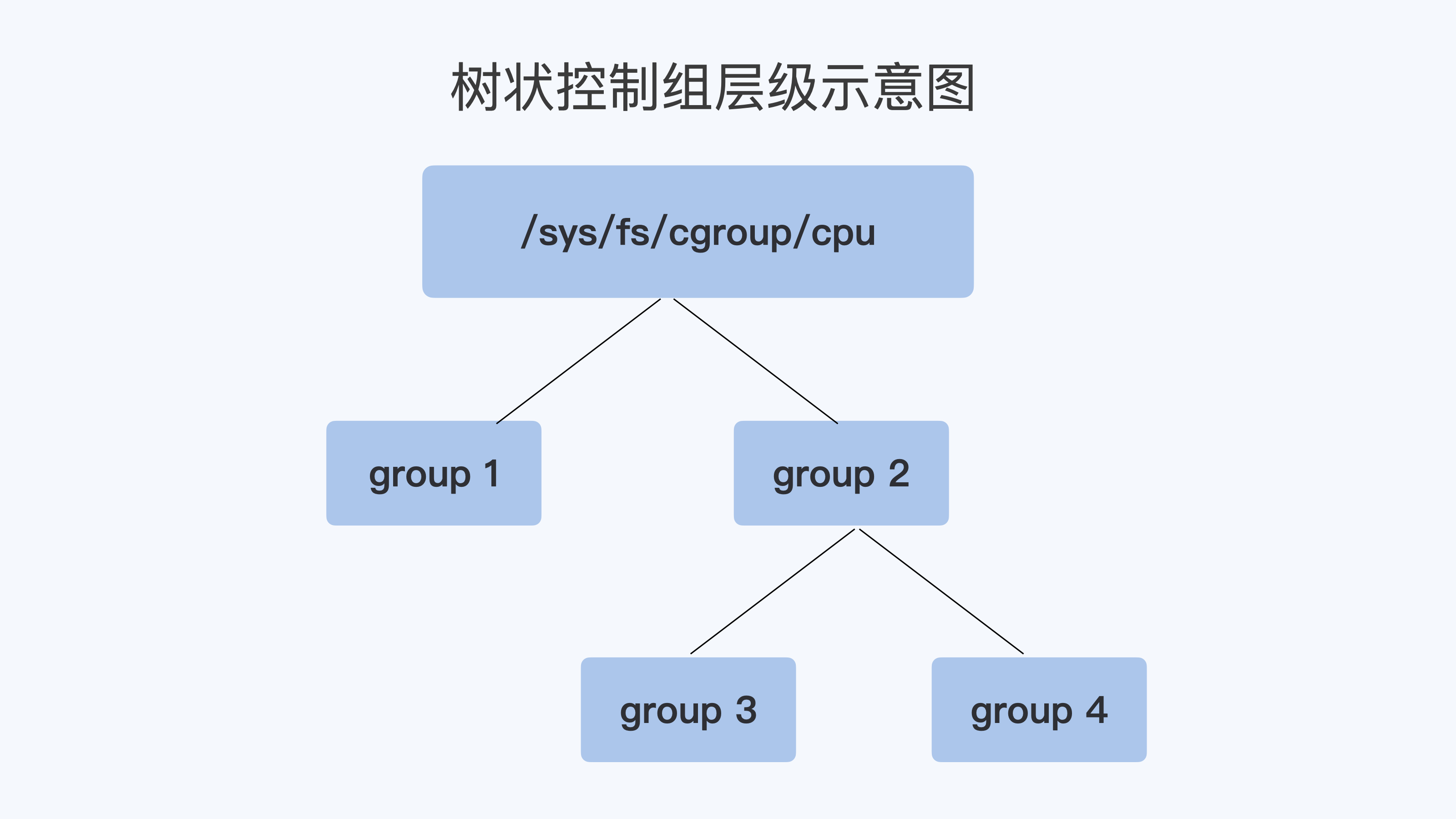
每个cgroups的子系统都是通过一个虚拟文件系统挂载点来管理。在linux发行版里,cpu cgroup一般是挂载到/sys/fs/cgroup/cpu目录下。在该目录下,每个控制组都是一个子目录,各个控制组之间的关系是一个树状的层级关系
例如,在子系统的最顶层目录开始创建两个控制组,其实就是创建两个目录group1与group2,然后再在group2下面创建两个控制组group3与group4,如此,便建立了一个树状的控制组层级,如下图所示
创建控制组后,会在目录下自动生成一系列文件,下面是一些关键文件
1 | cgroup.procs:把进程的pid号写到这个文件中,可以对这个进程做资源限制 |
补充:
k8s中有两个资源申请参数
request
只是一个初始的申请量,实际使用量以进程占用位置,可以在request的基础上继续超用的
limit
控制资源使用的上限,最多最多用到limit设置的值,但是能不能真的达到limit的限制,还需要考虑宿主机资源是否够用才行
memory cgroup
基本概念
介绍memory cgroup之前,需要先了解一下OOM机制。
OOM 全称 Out of Memory(内存不足/内存溢出),是linux系统的一种保护机制,当物理内存不够用时,linux系统的killer会杀死某个正在运行的进程来释放内存。OOM分为两种情况:整个系统级别,以及
操作系统级别。无论如何,只要宿主机内存不足,肯定会触发OOM,站在整个系统的角度去杀进程,所有进程都可能是目标。
cgroup控制组级别。宿主机内存充足,但是控制组内的进程对内存的占用超过了限制,触发OOM,只能杀死本控制组内的进程。
memory cgroup的使用
每创建一个容器都会创建一个容器的memory cgroup 控制组,在目录/sys/fs/cgroup/memory/system.slice/docker-xxx下。
主要关注三个参数:
1 | memory.limit_in_bytes:控制容器内所有进程可以占用的物理内存上限,如果父级group设置的memory.limit_in_bytes为500M,那么子group最多只能设置到500M |
OOM发生之后,还有一件重要的事情,就是查找OOM的日志,分析发生的原因,可以查看内核日志,执行journal -k或者查看/var/log/messages日志
三大块重要的内容:
1、找到容器的进程mem_alloc,可以看到占用的rss(物理内的页数,默认每页4kB),还有就是oom_score_adj
2、可以看到最后被oom killer杀死的进程的pid号
3、可以看到发生OOM的容器或者控制组时什么,即可以断定到底是哪个容器发生了oom,如果罗列出的是整个操作系统的进程,那可以断定发生的一次系统级的oom
有两上述三部分信息作为依据之后,我们接下来的处理方案无法两种
1 | 1、被OOM干掉的进程可能本身就是需要很大的内存,我们需要调大memory.limit_in_bytes |
page cache
首先给出一个现象:容器使用的内存达到了限制,并不一定会立刻启用OOM
上面的现象中,容器使用的内存,是指memory.usage_in_bytes参数,实际上这个参数的值=真正占用的物理内存rss+读写缓存page cache。
所以在一些场景,容器内在进行大量的读写,容器的内存使用memory_usage_in_bytes虽然达到了限制也不会oom,反而还能继续申请到内存,因为这些读写的数据会大量缓存到page cache里,memory_usage_in_bytes随即升高,因此整体内存用量很快就达到了最大限制,但此时的容器物理内存其实并没有真的用满,因为容器使用掉的内存里多半是给了page cache,而page cache占用掉的内存,是会被linux系统释放掉的。所以容器再申请内存并不会oom,而会触发linux的内存回收机制、采用lru算法回收内存,page cache里因为是一些缓存内存无关紧要,比起关键数据,cache里的肯定符合lru的最近肯定最少使用,自然是被优先释放的,这样就可以继续分配给rss使用了。
所以由于page cache的特性,一些读写频繁的容器会经常处于最大内存限制,这没问题,我们主要关注rss即可,只要rss没有接近最大限制,就不用担心。
swap分区
swap分区本质是拓展出的内存,在物理内存不够时,才进行Swap交换。启用容器是默认关闭swap分区的,因为memory croup的存在是可以及时杀死内存达到限制的进程的,但因为swap分区的存在,并不会立刻杀死进程。宿主机操作系统会不断把进程的内存数据交换到磁盘swap分区上,产生大量的磁盘IO,这会带来宿主机整体性能的下降,进而影响宿主机上其他进程或容器的影响。
但是有时候我们的程序是需要使用swap分区来防止内存突然暴涨,而被OOM killer干掉的。比如有些程序的启动需要进行大量的初始操作,需要占用很多内存,但是启动之后的内存没有那么大,所以我们如果给此类容器分配很大内存是不合理的,分配小了又会导致在启动阶段被OOM干掉,此时swap分区就显得很有用了。
关于如何使用swap分区,以及平衡swap与page cache的使用,参考:容器中使用swap分区
blkio cgroup
基本概念
VFS
VFS(Virtual Filesystem Switch)称为虚拟文件系统或虚拟文件系统转换,是一个内核软件层,是在具体的文件系统filesystem之上抽象的一层,用来处理与Posix文件系统相关的所有调用,表现为能够给各种文件系统提供一个通用的接口,使上层的应用程序能够使用通用的接口访问不同文件系统filesystem,同时也为不同文件系统的通信提供了媒介。
通俗的讲,VFS 设计的初衷就是要支持所有的文件系统,处理与 Unix 标准文件系统相关的所有系统调用,为各种文件系统提供一个通用的接口。
文件I/O的流程:
1 | 用户进程f.write() ----> 系统调用sys_write() ----> 虚拟文件系统VFS ----> 文件系统(ext4、xfs) ----> 缓存层page cache ----> 块存储Block layer ---> 硬件设备驱动 ----> 硬件设备(硬盘、usb) |
脏数据
介绍脏数据之前,需要先了解文件的io模式:
- Direct I/O:直接写入
- Buffer I/O:先把数据写到buff缓冲区,然后由内核异步把缓冲区的数据写入磁盘
在Buffer I/O的模式中,写数据是先写入了page cache,还没来得及写入磁盘,这部分数据称之为脏数据,即dirty pages。在linux内核中会有专门的内核线程(每个磁盘设备对应的kworker/flush线程)会定期负责把脏数据落到磁盘中。bufferd IO的读写效率更高,所以大多数场景使用的都是该模式。
该模式下,关于读和写需要考虑的内容还是有区别的:
读缓存在绝大多数情况下是有益无害的(程序可以直接从RAM中读取数据)。
写缓存比较复杂
- 写操作先将数据写入buff缓冲区,然后会等待内核线程把buffer里的脏数据写入磁盘,在等待的这段周期内,出现了一些类似断电、崩溃这种问题,就可能导致数据丢失。
- 一次性往磁盘写入过多数据,可能导致系统卡顿,因为系统缓存过大的情况下,操作系统可能会将异步写入切换为同步写入。
- 可能存在缓存被写爆的情况。
写缓存过大可能对系统造成影响,在不同场景下,可以通过修改内核参数来解决,参考 脏数据对容器读写性能的影响
blkio cgroup的使用
一台宿主机上运行的多个容器,容器的IO速率是彼此影响的,因为本质都是在用宿主机的I/O资源,为了规避这种影响,应该给每个容器都设置合理的IO性能,这时需要用到 blkio cgroup。
1 | blkio.throttle.read_bps_device # 限制设备的读带宽 |