
容器管理
容器进程管理
僵尸进程和孤儿进程
僵尸进程
linux操作系统的设计规定:父进程应该具备随时获取子进程状态的能力。 如果子进程先于父进程运行完毕,linux系统会将子进程占用的重型资源都释放掉(比如占用的内存空间、cpu资源、打开的文件等),但是会保留一部分子进程的关键状态信息,比如进程号,退出状态,运行时间等,此时子进程就相当于死了但是没死干净,因而得名”僵尸进程”,需要父进程查阅并回收。
如果存在大量的僵尸进程,会导致大量pid号被占用,可能无法创建新的进程,此时只能够杀掉父进程,让这些僵尸进程会被linux系统中pid为1的顶级进程(init或systemd)接管,顶级进程会定期发起系统调用wait/waitpid来通知操作系统清理僵尸儿子。
注意:父进程发起的wait或waitpid调用只能回收僵尸儿子,无法回收孙子辈。
孤儿进程
父进程先死掉,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。孤儿进程将被进程号为1的顶级进程(init或systemd)所收养,并由顶级进程对它们完成状态收集工作。
注意:孤儿只会被1号进程收养,而不是被它爷爷进程、或者太爷爷进程收养,这一点很关键。
容器的1号进程和0号进程
容器正常启动后,使用docker exec contaienrID bash进入容器后,使用ps命令,可以发现容器的1号进程。

1号进程是容器的首启动进程,容器的pid namespcae就是由1号进创建的,容内其余进程基本都是首启动进程的子孙进程。只要1号进程挂掉那容器便会关闭,pid namespace会被回收。
但是仔细查看会发现,1号进程存在父进程,它的父进程pid号是0,这个进程称为0号进程。
0号进程其实是一个docker-shim进程,每启动一个容器都会在宿主机产生一个docker-shim进程,当容器已经running之后,我们exec进入容器里执行命令产生的新进程,都是0号进程的儿子,而不是1号进程的儿子。所以说容器中的1号进程并不会像宿主机的1号进程那样直接或间接地领导所有其它进程。

上面的图中就是一个容器的docker-shim进程,如果这个进程挂掉,那么这个容器内的所有进程都会被回收。
另外如果用ps -ef查看这个docker-shim进程,会发现其实它也有父进程,它的父进程是宿主机的1号进程,就是systemd进程。按道理来说,containerd进程会为每个容器创建docker-shim进程,那么docker-shim进程的父进程应该是containerd进程才对,事实上这是因为containerd进程使用了setsid的方法,将docker-shim进程的父进程设置为了宿主机操作系统的1号进程,相当于把自己的子进程交给了宿主机的1号进程来收养和管理,这样只要宿主机操作系统还在运行,宿主机1号进程在运行,容器就能被正常的运行和管理。
这也是docker配置文件中 "live-restore": true的实现原理,即便docker守护进程重启或挂掉了,容器也不会挂掉。
综上所述,容器里的1号进程应该具备下面的能力:
1号进程需要在前台一直运行。只要容器里的1号进程停止,容器就会结束。
由于容器里的1号进程并不是init或者systemd,而是开发者自己写的,1号进程应该具备回收僵尸儿子的能力。
Containerd在停止容器的时候,会向容器的1号进程发送一个-15信号,如果容器内的1号进程没有信号转发能力,那在回收pid namespce时会向该namespace里的所有其他进程发送SIGKILL信号信号强制杀死。这通常会带来一些副作用,造成数据丢失或者终端无法恢复到正常状态等,所以容器的1号进程应该具备信号转发的能力。
容器内僵尸进程累积的解决方案
要解决容器内的僵尸进程,最简单粗暴的方式就是杀掉容器内的1号进程,这样容器内的僵尸进程会由容器的0号进程containerd-shim回收,但这并不是生产环境中的解决方案,因为1号进程一般是容器的业务进程,杀掉1号进程,容器会挂掉,业务就中断了。在一些情况下,我们必须要在容器的1号进程活着的情况下,解决僵尸进程累积的问题。
设置pid cgroup限制容器进程上限
这种方式并不能彻底解决僵尸进程的问题,只能避免单个容器内僵尸进程累积,占用全部的宿主机的pid号,对其他容器造成影响。
了解即可,一般是在k8s中配置
改进代码,使得1号进程具备回收僵尸进程的能力
改进代码,需要不只能让1号进程能够回收自己的儿子进程,当自己的儿子进程被回收之后,1号进程会接管自己的孙子进程,从pid号上来看,孙子进程变成了自己的儿子进程,但是在代码里面,1号进程可能并不具备这种能力,需要增加逻辑来实现这一功能,让1号进程也具有回收自己孙子进程的能力。
改变容器内的1号进程
让bash充当容器内的1号进程
可以编写一个bash脚本,把1号进程的启动命令放到bash脚本里面,然后把这个bash脚本作为容器的启动命令,这样bash进程就变成了容器的1号进程,bash进程肯定是具有完善的回收僵尸进程的能力的。
这个方案的缺点是bash不具备信号转发的能力,当停止容器的时候,无法做到平滑关闭子进程。
引入tini作为容器内的1号进程
tini是一个轻量级的init解决方案,具备收养孤儿,并定期回收僵尸儿子和信号转发的能力。
在Docker1.13及以后的版本中,tini已经集成进Docker-ce中,我们可以非常简便的在docker run的时候用–init参数来使用 tini,不需要在镜像中安装 tini,会自动注入tini程式 (/sbin/docker-init) 到容器中
1
docker run -d --init --name test1 image:lastest
如果是在k8s中,建议从镜像的角度解决,在制作镜像的时候加入tini,并改造容器的启动命令
1
2
3
4
5
6ADD tini /tini
RUN chmod +x /tini
ADD test.py /opt
ENTRYPOINT ["/tini","--"]
# Run your program under Tini
CMD ["/your/program", "-and", "-its", "arguments"]注意:tini默认是只给自己的儿子进程转发平滑关闭的信号(kill -15),要实现儿子进程的所有子孙进程都能够平滑关闭,还是需要业务代码里面注册并处理自己接收到的平滑关闭信号,然后转发给子孙进程的。
容器网络管理
Docker网络模式有四种:Bridge模式、Host模式、Container模式、None模式。
通过命令可以查看到三种网络模式:
1 | [root@test03 ~]# docker network ls |
none网络模式
使用none模式,Docker容器拥有自己的Network Namespace,但是,并不为Docker容器进行任何网络配置。也就是说,这个Docker容器没有网卡、IP、路由等信息。需要我们自己为Docker容器添加网卡、配置IP等,了解即可。
host网络模式
如果启动容器的时候使用host模式,那么这个容器将不会获取一个独立的Network Namespace,而是和宿主机共用一个Network Namespace。
这里和我们平常使用的虚拟机的仅主机模式不一样,容器将不会虚拟出自己的网卡,配置自己的IP等,而是使用宿主机的ip地址,包括主机名,端口等网络相关部分与宿主机是完全一致的。但是,容器的其他方面,如文件系统、系统进程等还是和宿主机或者其他容器隔离的。
注意:host模式下,容器内启端口占用的直接就是宿主机的端口,不需要做端口映射,同一个物理机上的多个容器都采用host网络直接监听物理机的端口容易发生冲突。
bridge网络模式
当Docker守护进程或者叫引擎启动时,会在主机上创建一个名为Docker0的虚拟网桥,该网桥就相当于一台虚拟的二层交换机
docker启动的容器如果指定为bridge网络模式(默认就是这种网络模式),则会连接到这个虚拟网桥上,相当于接入了一台二层交换机。
接入时,docker引擎会在主机上创建一对虚拟网卡veth pair设备,veth对成对出现且一一对应,相当于构建了一根网线,docker引擎会将veth pair设备的一端放在新创建的容器中,并命名为eth0(容器内部网卡),另一端在放在主机中,以vethxxx这样类似的名称命名,并将这个网络设备加入到docker0网桥中(可以使用brctl show命令查看,yum install -y bridge-utils。可以执行brctl showmacs docker0查看网桥里维护的mac地址表)。
如下图多个容器通过虚拟机交互机docker0接入了一个二层网络中,接入docker0时,docker引擎会从docker0子网中分配一个IP给容器使用,并设置docker0的IP地址为容器的默认网关。类似于vmware workstation里的NAT模式。
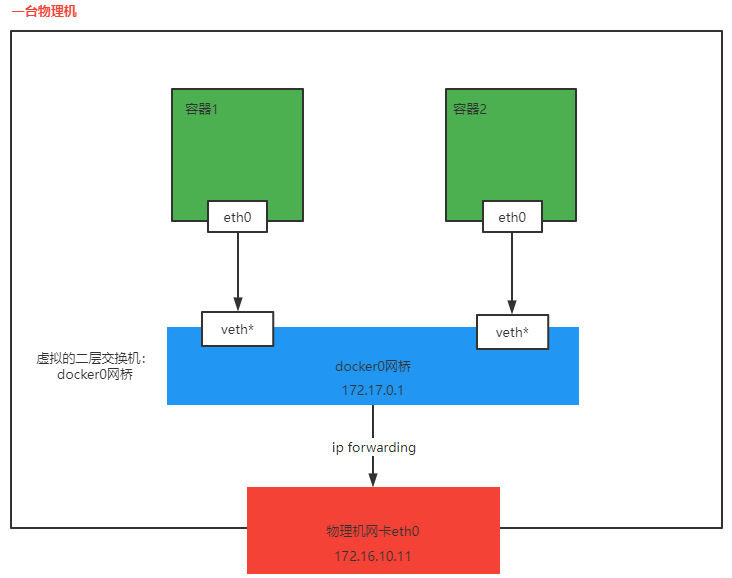
注意:bridge模式下,容器无法直接跨主机通信,映射本机端口才可以,所以跨主机互联比较麻烦。
container网络模式
这个模式指定新创建的容器和已经存在的容器共享一个Network Namespace,而不是和宿主机共享。新创建的容器也不会自己创建网卡,IP等。而是和一个指定的容器共享IP、端口范围等。同样,两个容器除了网络方面,其他的还都是属于隔离。两个容器的进程可以通过宿主机的lo网卡设备进行通信。
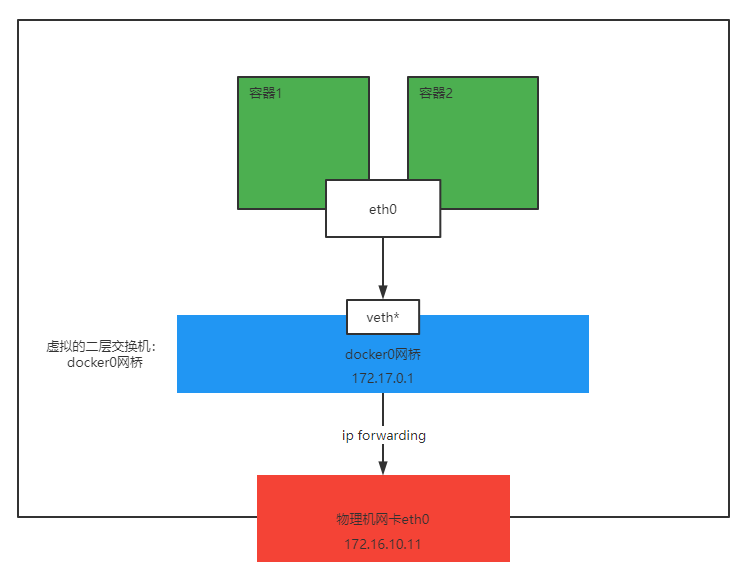
注意:container网络模式是多个容器共用一个隔离的网络,k8s中启动一个pod时会先拉起一个pause容器初始化网络环境、存储等,然后再拉起业务容器与pause容器共享网络,采用的就是类似原理。
容器存储管理
因为容器里的文件系统是overlayFS,容器内发起的写操作到overlayFS之后,到操作系统之后还需要转换成操作系统的文件系统(例如ext4、xfs)的写操作。所以如果容器内涉及到频繁的写操作,建议给容器挂载单独的volume。
默认情况容器内的可用磁盘空间是没有限制的,在没有挂载任何外部存储卷的情况下,容器内的写操作,无论是写文件,还是输出到标准输出,其实都是写到了upperdir层,也就是写到的宿主机上,所以如果不加以限制,很有可能会发宿主机磁盘空间写满。为了避免这种情况发生,有必要对容器的磁盘配额进行限制,同时控制容器的日志大小。
对容器可用磁盘进行配额
单独限制某个一个容器
1
docker run -d --name test --storage-opt size=100M centos:7 tail -f /dev/null # 限制100M
设置全局的默认值,编辑
/etc/docker/daemon.json1
2
3
4
5
6
7{
"storage-driver": "overlay2",
"storage-opts": [
"overlay2.override_kernel_check=true",
"overlay2.size=1G" # 设置1G的磁盘配额
]
}
控制容器日志的大小
每个容器都有自己的日志,用来接收标准输出的内容,查看路径:docker inspect container_name | grep -i logpath
单独限制某个容器
1
docker run -it --log-opt max-size=10m --log-opt max-file=3 redis # 单个日志最大数值和最大日志数目
设置全局的默认值,编辑
/etc/docker/daemon.json1
2
3
4
5
6
7{
"log-driver":"json-file",
"log-opts":{
"max-size" :"50m", # 一个容器日志大小上限是50M
"max-file":"3" # 可以存在的最大日志文件数,超过最大值会删除最旧的文件。仅在max-size设置时有效。默认为5。
}
}注意:需要重启docker服务,已存在的容器不会生效,需要重建才可以
补充:k8s使用containerd作为容器运行时,通过kubelet参数控制静态pod日志大小
k8s中kubelet负责管理一些静态pod,如果想要控制这些静态pod的日志大小,可以通过调整kubelet的启动参数来实现,具体做法是:
在具体的某个节点上,通过systemctl status kubelet查看kubelet系统服务的配置路径
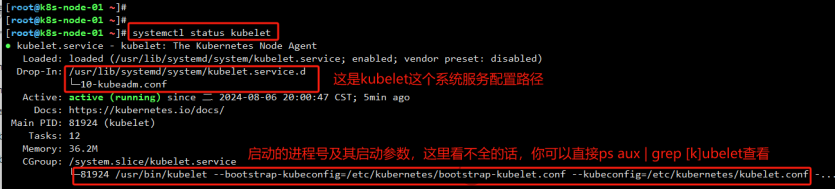
查看/usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf,获取kubelet进程的参数文件

编辑参数文件/var/lib/kubelet/kubeadm-flags.env,新增启动参数--container-log-max-files=5 --container-log-max-size='5Ki',重启kubelet即可。
迁移docker数据目录
1、停掉当前主机运行的容器
2、停掉docker服务
3、新增一块大盘,制作文件系统,挂载到一个新目录/data(做成lvm之后再挂载)
4、迁移数据(cp -ra /var/lib/docker /data/docker)
5、修改docker的配置文件,将数据目录执行新目录/data/docker
6、重新启动docker服务
7、启动容器